AI時代のデータ資産価値と構築ロードマップ― なぜ今、データ未整備が経営リスクになるのか―

 AIによる概要
AIによる概要
この記事は、生成AIの普及によってデータの価値が「意思決定の補助材料」から、AIを実務に落とすための前提条件(燃料)へと決定的に変化したことを論じています。LLMがコモディティ化するほど差別化要因は企業固有のプロプライエタリ・データに移り、RAGやファインチューニングを通じて「社内の正解」に接地させられる企業だけが、AIを業務インフラとして機能させられるという視点を提示します。
- 競争優位はモデルではなくコンテキストで決まる:LLMが誰でも使える時代ほど、成果差は企業固有データの整備・運用で生まれる。
- RAGは「社内根拠でAIを動かす」標準アーキテクチャ:検索可能なデータが整っていない企業はAIを実務投入できない。
- 未整備データはハルシネーションを経営リスクに変える:価格・契約・法務・安全に直結する誤りが現場へ混入しやすくなる。
- データ価値は定量化できる:IVI(品質)、BVI(業務)、PVI(KPI)、CVI(損失回避)など複数の物差しで投資判断へ落とせる。
- データ資産構築は段階戦:可視化→正本化→運用化→AI接続の順で進め、最小ガバナンスとセキュリティを「資産保全」として設計する。
この記事を読むことで、生成AI時代におけるデータの役割が「分析のため」から業務を動かすための基盤へ移った理由が整理でき、RAGや運用・ガバナンスを含めてAI活用の成否がどこで決まるかを理解できます。そのうえで、自社のデータ整備を投資判断できる言語(価値指標)に落とし込み、どの順番で資産化を進めるべきかの現実的な行動方針を描けるようになります。
データが経営に重要であること自体は、AI以前から繰り返し語られてきた。顧客データを用いたパーソナライズ、購買・在庫データを用いた需要予測、現場データを用いた歩留まり改善。これらはデータ活用の代表例であり、一定の成果が出ている企業も少なくない。
しかし、生成AIの普及以降、データの「重要性」は同じでも、重要である理由が決定的に変わってきている。
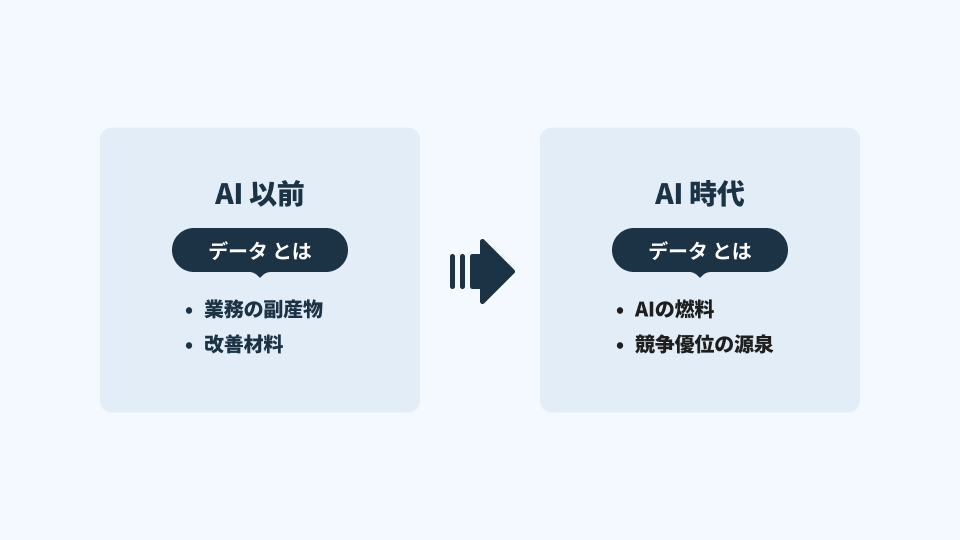
以前のデータは主として「意思決定を補助する材料」だった。経営判断の速度や精度を上げるための武器ではあるが、極端な話、データが弱くても人が気合いで回す余地があった。データが散らばっていても、経験者が頭の中で補正し、現場が阿吽の呼吸でなんとか前へ進める。そういう“帳尻の合い方”が成立していた。
一方、AI時代のデータは、AIを実務に落とすための前提条件である。確かにAIは“賢い”が、それは汎用知能としての賢さであり、個社の業務文脈・顧客関係・判断ルールを自動的に理解しているわけではない。そこで差がつくのが、AIに与えるべき「燃料」、すなわち 自社固有のプロプライエタリ・データである。IBMも、生成AIにおける競争優位の源泉として、企業固有データがAI出力を業務文脈に“グラウンディング(接地)”させる点を強調している。[1]
この変化は、「AIツールの使い方」だけでは決して埋まらない。ツールの習熟は参入条件に過ぎず、AI時代における差別化はデータ資産の設計と運用からしか生まれない。
なぜAIはデータ価値を飛躍させたのか
LLMのコモディティ化によって差別化要因は「コンテキスト」へ移る
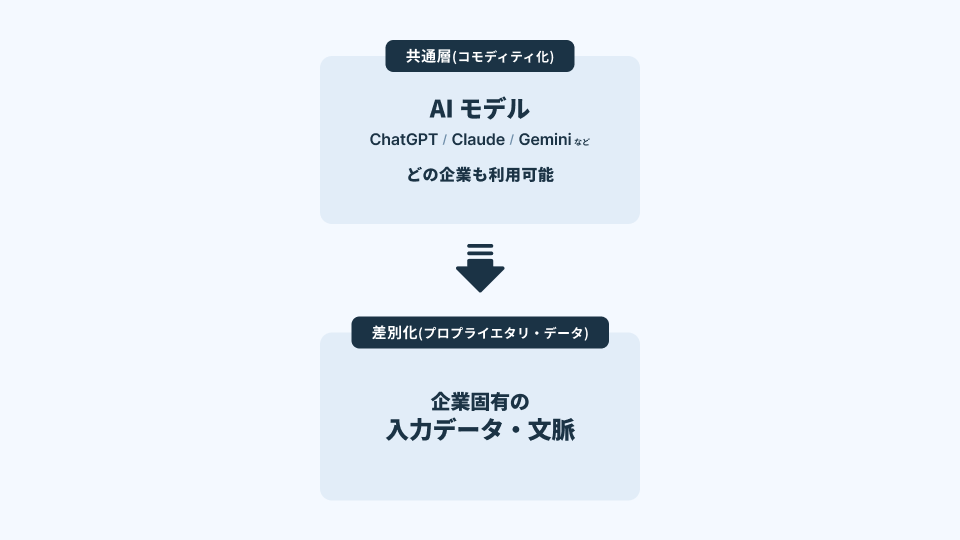
生成AIの基盤モデル(LLM)は、API/SaaSとして誰でもアクセスできる。ここで起きるのは、競争軸の反転である。
以前は「どのシステムを導入しているか(ツール差)」が効き、データは意思決定の補助材料という位置づけだった。ところが現在は、同じAIを使っても成果が大きく割れる。その差を生むのは、AIが“何を参照しているか”、つまりデータ側だ。
言い換えれば、AIの普及は「モデルの民主化」を進めたが、同時に「コンテキストの格差」を顕在化させた。AI時代の差別化は 「エンジン(モデル)」ではなく「燃料(プロプライエタリ・データ)」で決まる。企業固有データがAIを特定業務に適合させ、出力を“企業内の正解”へ寄せる。[1]
この構造が意味するのは、単なる「データの重要化」ではない。データが競争優位の一次要因に昇格した、ということである。
生成AIの価値は「生成」ではなく「実務遂行」
生成AIが普及した初期は、「文章を作れる」「要約できる」といった生成機能が注目された。しかし、企業が本当に欲しいのは“生成”そのものではない。実務が前に進むことである。
実務が前に進むとは、たとえば次のような状態だ。
社内ルールに整合した回答を返す。最新の価格・仕様・契約条件に沿って提案する。担当者ごとの対応履歴を踏まえて顧客対応を行う。例外処理や過去の失敗を避けた判断をする。
ここまで来て初めて、AIは「便利な文章生成ツール」ではなく、現場の推進力として機能し始める。
ただし、このレベルに到達するには、AIが「社内の正解」を参照できなければならない。そこで必要になるのがRAG(検索拡張生成)であり、場合によってはファインチューニングである。
RAG(検索拡張生成)が示す「データ前提社会」
RAGとは何か(“社内根拠”でAIを動かす標準アーキテクチャ)
RAGは、LLMに社内データ(文書・FAQ・仕様書・議事録・規程・顧客対応履歴等)を検索させ、その検索結果を根拠として回答を生成させる仕組みである。RAGによって、検索結果の最新性・正確性・説明可能性を同時に引き上げられる。
しかし、このアーキテクチャが本質的に要求するのは、「検索可能なデータ」である。紙は検索できない。画像PDFは検索できない(OCRをしても品質次第)。個人PCのExcelは検索対象として統合されていない。メールの属人的運用は権限・参照設計が破綻しやすい。
つまりRAGは、データ整備の遅れを隠せない形で露呈させる。逆に言えば、RAGが普及するほど「データ未整備の企業はAIを実務投入できない」状態が一般化する。
ハルシネーションを“経営リスク”に変えるのが、未整備データである
LLMのハルシネーション(もっともらしい誤り)は、消えるわけではない。だからこそ、RAGで「根拠を与える」設計が現場標準になる。RAG等の外部知識付与がハルシネーションを減らし得るという整理も存在する。[2]
ここで重要なのは、ハルシネーションが単なる品質問題ではなく、契約・価格・法務・安全に直結する“経営リスク”になるという点だ。データが整備されていない企業では、AIに根拠を与えられず、AIの誤りが現場に混入しやすくなる。すると、誤った見積・誤った条件で顧客へ提案し、逸失利益や信用毀損を招く。誤った手順で作業し、事故や品質問題につながる。誤った規程解釈をし、コンプライアンスリスクを抱える。
「AIを使えば便利」どころか、データ未整備のままAIを使うほど、事故の確率が上がる。この構造が、データ価値を“防衛的価値”としても押し上げている。
ファインチューニングが示す「データ品質の資産性」
RAGがデータ「参照」であるのに対し、ファインチューニングはモデルの重み自体を調整して“癖”を付ける。適用領域は慎重に選ぶべきだが、定型業務の出力品質を継続的に安定させたい、書式や分類基準、社内用語を強制したい、固有の判断パターンを再現したい――こうした場面では現実解になり得る。
ただし、ここで要になるのが「学習データの品質」だ。ファインチューニングは、表記揺れ、欠損、矛盾、古いルール混入に対して成果が素直に悪化する。つまり、AI時代のデータは「量」より「整合性」と「鮮度」が資産価値を規定する。
デジタルデータの定量的「資産性」
データが資産であるなら、経営としては最低限「どのデータがどれだけの価値を持つか」を語れなければならない。ここで重要なのは、“会計上の資産計上ができるか”ではない。資産計上が難しくても、データが企業にもたらす価値は、意思決定と投資配分の論理として整理できる。むしろAI時代は、その整理を怠った企業ほど、データ整備を「なんとなく良さそう」「誰かが言っているから」といった空気で進めてしまい、結果として中途半端な施策に終わりやすい。
このとき実務に効く考え方として、ダグラス・ラニーの提唱する Infonomics(情報の資産管理・価値測定の体系)がある。[3] Infonomicsが優れているのは、「データを売れるか」だけで価値を測ろうとしない点だ。データ価値を複数の物差しに分解し、経営が投資判断できる言語へ落としていく。つまり、データ活用を“設計”へ引き戻すためのフレームである。

Intrinsic Value of Information(IVI)
データ品質そのものの価値を測る
最初に押さえるべきは、「データ品質そのものに価値がある」という視点である。内在価値は、データがどれだけ正確で、完全で、矛盾がなく、そして更新されているかといった“素材としての強さ”を問う。Infonomicsの整理でも、内在価値は「どれだけ正しく、完全で、希少か」という観点で捉えられている。[3]
AI時代にこの観点が重要になる理由は単純だ。AIは、入力されたデータの品質を“自動補正”してくれるわけではない。むしろ、品質の悪いデータは、AIの出力の誤りや不整合として顕在化し、現場で事故を起こす。つまり、内在価値の劣化は、そのまま「実務遂行能力の劣化」に変換されるため、IVIは資産価値の根本指標になる
実務上では、次の指標群に落とすことができる。
- Validity(正確性):サンプル監査で誤り率を測る
- Completeness(完全性):必須項目の欠損率を測る
- Uniqueness(重複率):顧客マスタ等の重複率を測る
- Timeliness(鮮度):更新遅延(日数)を測る
- Consistency(整合性):基幹・CRM・請求で矛盾がない比率を測る
たとえば顧客マスタであれば、電話番号の欠損率、住所の表記揺れ、法人名の揺れ、担当者情報の未更新率などが典型になる。ここで重要なのは、これらが単なる“データ担当者の困りごと”では終わらない点だ。欠損や揺れは、検索精度の低下としてRAGに影響し、顧客照会の誤りとして現場へ混入する。現場がAIを信用しなくなり、PoCが止まり、最終的に「AIは使えない」という結論へ収束する。こうした失敗の大半は、モデルの性能ではなく、データの内在価値が担保されていないことに起因する。
ここまでくると、内在価値は「整備できたら良い」ではなく、「整備されていないと始まらない」条件である。
Business Value of Information(BVI)
業務プロセスに与える価値(時間・コスト・品質)で測る
次に、データが業務プロセスへ与える価値を考える。業務価値は、時間、コスト、品質にどう効くかという、より直接的な物差しだ。Infonomicsでも業務価値は「特定目的に対する関連性・有用性」として整理される。[3]
ここが重要なのは、データ投資が経営にとって「費用」に見えやすいからである。データ基盤の整備は、売上を直接増やす施策のようには見えない。しかし、業務価値の観点を導入すると、投資は“抽象的な未来”ではなく、“具体的な改善”として説明できるようになる。
たとえば受発注業務を考える。受注入力に12分、確認と差戻しに4分かかり、月2,000件あるとする。ここで顧客マスタと商品マスタ、単価表、与信、配送条件などが整備され、入力と照合の大半が自動化されれば、受注入力が4分、差戻しが1分になる、といった改善が現実的に起きる。削減時間は月間で数百時間規模になり、人件費換算すれば100万円単位の改善へつながる。これは大企業の話ではない。中小企業ほど、属人的オペレーションと“確認作業”が膨らみやすいので、改善幅が大きい。
また、業務価値は「作業時間の短縮」だけではない。品質、つまりミスの減少もここに含まれる。見積や請求の条件の誤りが減ること、手戻りが減ること、クレームが減ること。これらは現場が本当に苦しんでいるコストであり、データ整備が“儲け”へ転換される入口でもある。
業務価値を実現するには、必ずしも大規模なDWHから始める必要はない。まずは業務アプリ側(Kintone等)で入力の型を強制し、Excelの使い勝手を残しながら構造化を進める。そのうえで、必要に応じてELTで集約し、DWHで分析やRAGに接続する。この順番が成立するからこそ、中小企業でも業務価値の回収が現実的になる。
Performance Value of Information(PVI)
KPIへの寄与で測る(売上・粗利・解約率・成約率など)
業務価値が「プロセス改善」だとすれば、成果価値は「KPI改善」である。売上、粗利、成約率、解約率、不良率、納期遵守率。データが企業の成果にどう寄与するかを問う観点である。[3]
AI時代に成果価値が跳ねやすい理由は、AIが“文章生成”を超えて「判断の分岐」を扱えるようになったからだ。ここがAI以前との決定的な差である。以前のデータ活用は、分析結果を人が読み、会議で議論し、施策へ落とすという手順を踏んでいた。人の意思決定を前提としていたため、ボトルネックは常に“組織の意思決定速度”だった。
一方、AIを業務へ組み込むと、判断の分岐そのものがワークフローに組み込まれる。たとえば営業提案では、顧客の過去履歴、失注理由、価格交渉の傾向、要望の変遷などを参照し、「この顧客にはどの条件提示が刺さりやすいか」「どこで摩擦が起きやすいか」を提案へ反映できる。これは単なる文章生成ではなく、実務の意思決定を部分的に代替している。
ただし、ここでも前提条件がある。成果価値を取りに行くほど、参照するデータの品質・鮮度・正本性が重要になる。誤った履歴を参照して最適化をかければ、成果を上げるどころか悪化させる。つまり、成果価値は魅力的だが、その分“資産としてのデータ整備”が要求される。
Market Value / Cost Value(MVI / CVI)
データが“売れるか”より、まずは“失ったらいくら損か”で測る
「データが売れるか」という問いは分かりやすい。しかし、多くの中小企業にとって、当面の主戦場はそこではない。データを外部販売する市場価値(MVI)を追う以前に、まず問うべきは「失ったらいくら損か」である。損失回避価値(CVI)は、データ資産を“防衛”という観点で測る物差しであり、実務に落としやすい。[3]
CVIを考えるとき、経営が見るべきは「事故が起きたときの最悪ケース」だけではない。より現実的なのは、復旧コスト、逸失利益、追加費用、信用毀損が、どの程度の確率で、どれほどの規模で起き得るかという期待値の発想である。復旧のためにどれだけの人件費が必要か。受注停止や対応停止が何日続くか。顧客対応・謝罪・法務対応にどれほどのコストがかかるか。取引停止や更新停止がどれほどの確率で起こり、将来の売上へどう影響するか。
ここまで整理すると、セキュリティ投資は「保険」ではなく「資産保全投資」になる。IPAも中小企業向けガイドラインで、サイバーリスクを経営課題として扱う必要性を明確にしている。[4] AI時代は、データの価値が上がるほど、狙われる価値も上がる。つまり、攻撃のインセンティブが強まる。ここが“データ資産化”の現実である。
データ未整備が“経営リスク”になる理由
「データ整備は重要」という話が浅く見える最大の理由は、未整備であることの損失が、日々の現場では“静かに”発生するからだ。見積を作るのに時間がかかる、請求の確認が増える、引き継ぎがうまくいかない、問い合わせ対応が属人化する。こうした負担は、忙しさの中で「うちの会社はそういうもの」として飲み込まれやすい。しかしAI時代は、この静かな損失が“企業の参加資格”へ接続される。つまり、放置しても回る状態ではなくなる。
未整備の本質は「AIエコシステムと接続できない」こと
AI時代の業務ツールは例外なく、データ連携を前提に進化している。AIエージェント、ワークフロー自動化、BI、予測、最適化。どれもAPI・イベント・データモデルが前提であり、要するに「機械が読める形で整っているデータ」が必要になる。
このとき、データ未整備企業が直面するのは「便利なツールを導入できない」程度の話ではない。
- データが散在し、正本がない
- 更新が属人化し、鮮度が担保できない
- 権限設計がなく、共有できない
- 形式が統一されず、機械可読性がない
この状態でAIを導入できても、使うほどに事故が増える。AIに参照させるべき“企業内の正解”が存在しないからである。結果としてAI活用は、汎用的な文章生成に閉じ、差別化にならない。むしろ、誤りが現場に混入しやすくなり、慎重な組織ほどAI導入にブレーキがかかる。
ここで起きているのは、AIの性能問題ではなく、「データが資産として成立していない」という経営課題である。
「2025年の崖」は、データ資産の視点で読み替えられる
日本のDX文脈で象徴的なのが「2025年の崖」である。経済産業省のDXレポートは、レガシーシステムの複雑化・ブラックボックス化がDXを阻害し、放置した場合の損失シナリオを提示している。[5]
この議論は、単なるシステム刷新の話に見えるが、データ資産の観点で見ると本質はさらに明確になる。
- 既存システム上のデータが取り出せない
- 取り出せても定義が分からない(ブラックボックス)
- 統合できず、企業としての“唯一の真実”が作れない
- AI・自動化のためのデータ連携ができない
つまり「2025年の崖」とは、技術的負債の問題であると同時に、データ資産の形成不能という経営課題である。この潮流は、「データ接続できない企業」は、AI以前にデジタル競争から脱落する、という現実を示している。
近年のモダナイゼーションに関する報告が改めて取りまとめられていることも、この流れが一過性ではないことを示している。[6]
AIが話題になったからではない。競争環境そのものが、データ前提へ移行している。
サプライチェーン排除は「データ提出能力」で決まる
サプライチェーンにおけるデータ要求は、努力目標ではなく取引条件へ移行しつつある。たとえばトヨタのサプライヤー向け要件では、CO2削減目標やScope3等に関する要求、報告サイクルなどが具体的に示されている。[7]
ここで押さえるべきは、提出内容の難しさ以前に「提出を継続できる仕組みがあるか」が問われる点だ。
紙・属人Excel・手作業集計では、要求が増えるほど耐えられなくなる。最初は頑張れても、担当者が変わると崩れる。集計の根拠が追えなくなる。監査対応ができなくなる。結果として“外される”。これは競争ではなく、適格性審査である。
つまり、データ未整備は、現場の非効率というよりも、企業の立ち位置そのものを危うくする。
M&A・事業承継で起きているのは「アナログ・ディスカウント」である
会計上、データは資産計上されにくい。しかしM&A市場では、データ整備状況が企業価値に織り込まれる。理由は単純で、買い手が「統合(PMI)」のコストと成功確率を企業価値に織り込むからだ。
データが整備されていれば統合が早く、シナジーが出やすい。データが散逸していれば、統合に追加投資が必要で、事故確率も高い。この差は買収価格(マルチプル)に直結する。ここで起きているのが、いわば「アナログ・ディスカウント」である。
この局面では、データは“活用できたら良いもの”ではなく、“整備されていないと評価が下がるもの”になる。つまり、データ資産化はすでに市場の一部で始まっている。
まずは企業の現状把握とデータスタックを知る
「現実的なデータ資産構築ステップ」に入る前に自社の現在地を把握し、正しいロードマップを引くべきである。実務で一番多い失敗は、「やる気はあるが、順番が違う」というタイプである。言い換えると、目指す姿を描く前に、現在地を見誤っている。
ここでは、まず企業の現在地を客観的に把握するための枠組みとしてデータ成熟度モデルを置き、その後に「身の丈に合うが拡張性のある」リーンなデータスタックの考え方を整理する。
データ成熟度モデルで「現在地」を言語化する
最初に必要なのは、自社がどの段階にいるかを客観的に評価することだ。
この評価が曖昧なままだと、「本当は整備が先なのにAIを触り始める」「本当は統合が先なのにダッシュボードから作る」といった、順番の逆転が起きる。
成熟度モデルは大きく4段階で整理できる。
データ探索期(Data Exploring)
情報が紙、メール、個人PC内のExcelに散在し、“Excel地獄”になっている状態。バックアップも不全で、意思決定は勘と経験に寄りがちだ。ここでやるべきは、いきなり高度な分析ではない。まずは業務のデジタル化、SaaS導入、紙業務の廃止といった「土台づくり」である。
データ認識期(Data Informed)
会計ソフトやCRMなどは導入済みだが、システム間が連携していない。レポート作成が手作業のコピペになり、結局“統合されていないデジタル”として疲弊する段階だ。ここで必要なのは、ETL/ELTなどの仕組みによるデータ集約と、データウェアハウス構築である。
データ主導期(Data Driven)
統合・可視化が進み、Single Source of Truth(唯一の真実)が確立され、KPIがリアルタイムでダッシュボード化される。部門横断の活用が始まり、ようやく「会社として同じ数字を見る」状態が生まれる。
データ変革期(Data Transformed)
AIがデータを参照して予測や生成を行う(RAG)。データが新たなビジネスモデルを創出し、カスタムAIモデルやデータ収益化の議論が現実味を帯びる段階だ。
ここで重要なのは、「理想は第4段階」だとしても、多くの企業にとって当面の勝負所は第1/2段階から第3段階へ上がれるかという点にある。少なくとも“唯一の真実”がないままでは、AI以前に社内の意思決定が割れるからだ(そしてAIはその割れを拡大する)。「2025年の崖」を回避するうえでも、ステージ1/2から3へ移行することが急務だという指摘は、この現実を端的に言い当てている。
中小企業向け「リーン」データスタックという現実解
次に押さえるべきは、「何を揃えるか」ではなく、どんな思想でデータ基盤を組むかである。中小企業がデータドリブンに変革する際、最初から高額なエンタープライズ製品を導入する必要はない。身の丈に合いつつ拡張性のある“モダン・データ・スタック”の発想を採用すべきである。
そして、その現実性を担保する条件が「Pay-as-you-go(使用量課金)」である。現代のデータ基盤はサーバー購入が不要で、使用量に応じた課金体系のため中小企業でも導入しやすい。
リーンなデータスタックは、大きく言えば次の3要素で捉えると理解しやすい。
データの収集・統合(ELT)
主流であるETL(加工してから保存)に対し、モダンデータスタックではELT(先にそのままクラウドに放り込み、後から加工)が採られやすい。
この転換が中小企業に与える意味は大きい。最初から完璧なデータモデルを作り込まなくても、まず集めて、必要に応じて整える、という段階的な進め方ができるからだ。ツールとしてはFivetranやAirbyte(オープンソース版あり)が例示され、Salesforce、Shopify、Google広告、Kintone等を自動的に吸い上げて一箇所に集約できる、と整理されている。
データの保存(クラウドデータウェアハウス)
データの倉庫にあたるDWHは、Snowflake、Google BigQuery、Amazon Redshiftなどが代表例として挙げられる。
ここでのポイントは「高機能だから」ではない。中小企業にとってのメリットは、ストレージコストが安価で、サーバーメンテやパッチ適用が不要で、クエリ実行時だけ課金されるといった“運用負担の外部化”にある。
つまり、データ基盤を“保守する会社”になる必要がなく、事業側の判断と改善に集中できる。
ノーコード/ローコードによる業務アプリ(Excelの置き換え=Shadow ITの解消)
専任データエンジニアを雇用できない中小企業にとって、Excelの使い勝手を維持しながらデータベース化できるツール選定は最重要――という問題提起は、現場の実情にそのまま刺さる。
具体例としてKintoneが挙げられ、ドラッグ&ドロップで業務アプリを作れること、そしてExcelと違ってデータに構造(型)を強制できるため品質が保たれること、さらにAPIが充実して将来的なAI連携も容易だ、と整理されている。
この3要素は、あなたの原稿にある「Excelを入力UIとして残し、裏側をDBにする」という現実解とも矛盾しない。むしろ、“現場の入力摩擦を増やさずに、構造化だけを進める”という考え方を、技術的に成立させるための部品がここに揃っている、と捉えるとよい。
現実的なデータ資産構築ステップ
データ資産構築は「IT施策」ではなく「経営プロジェクト」である
まず最初に、データ資産構築は、IT部門に丸投げできる施策ではない。
なぜなら、データの正しさ・更新ルール・利用範囲は、
最終的に 経営判断・業務ルール・責任分界 に行き着くからである。
- このデータは「会社としての正解」か
- 誰が最終的な正しさに責任を持つのか
- どの業務判断に使ってよいのか
- どこから先は人が判断すべきか
これらはツール選定では決まらない。
経営としての意思決定事項である。
したがって、ロードマップの入口で経営が問うべきは「どのツールを使うか」ではなく「自社は、どの業務判断をデータ(AI)に委ねたいのか」である。委ねたい判断が明確になって初めて、必要なデータ、必要な品質、必要な正本、必要な運用が逆算できる。
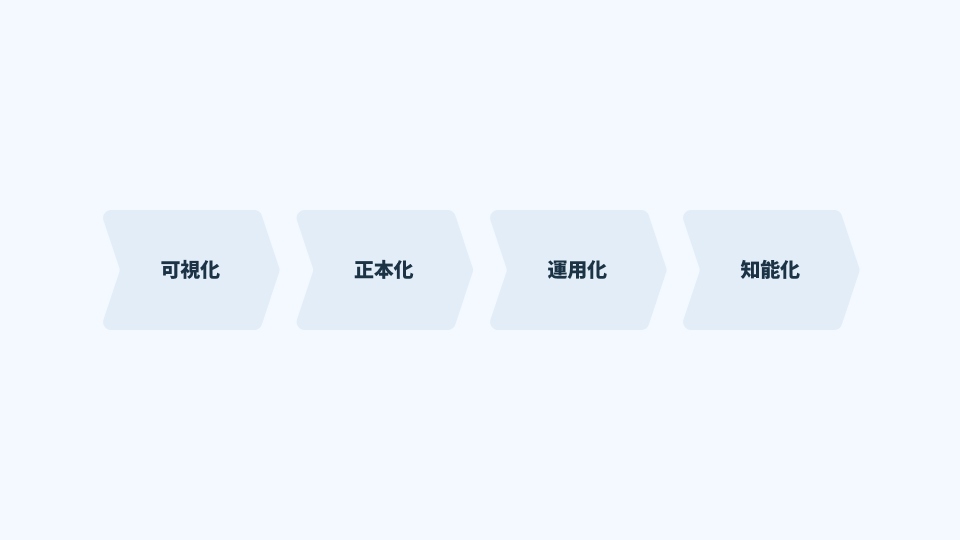
この前提を置いた上で、フェーズの全体像は次の四段階で捉えるのが実務的である。
フェーズ1:可視化(Data Visibility)
- 何のデータが、どこに、どの形式で存在するか把握する
- 目的:「知らない状態」からの脱却
フェーズ2:正本化(Single Source of Truth)
- データの正解を一つに決める
- 目的:「判断がぶれない状態」を作る
フェーズ3:運用化(Operationalization)
- 日常業務でデータが自然に更新される状態を作る
- 目的:「溜まるが使えない」を防ぐ
フェーズ4:知能化(AI / Automation)
- AI・自動化・予測を業務に組み込む
- 目的:意思決定・実行を加速する
フェーズ1:データ棚卸しを「資産台帳」として行う
1)データ棚卸しの誤解
多くの企業で行われるデータ棚卸しは、
「システム一覧」「ファイル一覧」で終わる。
しかし、資産構築の観点では不十分である。
必要なのは IT棚卸しではなく「データ資産台帳」 である。
2)最低限作るべき「データ資産台帳」の項目
以下は、ほとんどの企業において必須となるであろう項目である。
| 項目 | 内容 |
|---|---|
| データ名 | 顧客マスタ、受注履歴、日報 等 |
| データ種別 | マスタ / トランザクション / ログ |
| 保管場所 | システム名 / クラウド / Excel |
| 利用業務 | 営業、請求、保守 等 |
| 更新頻度 | リアルタイム / 日次 / 月次 |
| 正本か | Yes / No |
| データオーナー | 最終責任者 |
| 機密区分 | 公開 / 社内 / 限定 |
| AI利用可否 | 可 / 条件付き / 不可 |
ここでポイントなるのは、「AI利用可否」を必ず入れることだ。
これは後工程で、
- RAGに入れてよいか
- ファインチューニングに使ってよいか
- 社外LLMに送ってよいか
を判断する基準になる。
3)このフェーズでの経営判断
フェーズ1で経営が行うべき判断は、次の3点のみでよい。
- どのデータを「資産」と見なすか
- 誰がそのデータに責任を持つか
- AIに使ってよい範囲はどこまでか
これ以上の細部は、現場とITに委ねてよい。
フェーズ2:正本化(Single Source of Truth)の設計
1)正本化とは「システム統一」ではない
誤解されがちだが、
正本化=「全部一つのシステムに入れる」
ではない。
正本化とは、
「どれが正しいかを決める」ことである。
- 顧客名の正解はCRM
- 請求金額の正解は会計
- 契約条件の正解は契約管理
といった形でよい。
2)正本が決まらないと何が起きるか
正本が曖昧な状態でAIを使うと、
次の問題が必ず起きる。
- AIが複数の異なる数値を返す
- 現場が「どれが正しいか」で混乱する
- AIの出力が信用されなくなる
これは技術の問題ではない。
ガバナンス不在の問題である。
3)データオーナー制度(最小構成)
必要なのは、重厚なデータガバナンスではない。
最低限、以下だけでよい。
- データごとに 「最終責任者」 を1人決める
- 定義変更・項目追加はその人が承認する
- AI利用範囲の変更も同じ人が判断する
これだけで、
AI活用時の事故確率は大きく下がる。
フェーズ3:運用化―「入力させる」のではなく「勝手に溜まる」設計へ
1)データが溜まらない最大の理由
データが溜まらない原因は、
ほぼ例外なく 「入力が面倒」 である。
- 二重入力
- 目的が見えない入力
- 後で使われない入力
これらは必ず形骸化する。
2)運用化の原則:業務フローに埋め込む
運用化で守るべき原則は1つ。
「入力が業務の副産物になる状態を作る」
例:
- 見積作成 → 自動で案件データが残る
- 日報提出 → 進捗・課題が構造化される
- 問い合わせ対応 → FAQ候補が溜まる
ここで初めて、
データは「管理対象」ではなく
自然に増える資産になる。
3)Excelから抜け出せない企業の現実解
現実問題として、
いきなりExcelを捨てる必要はない。
重要なのは、
- Excelを 入力UI として残す
- 裏側はデータベースに保存する
という構造だ。
これにより、
- 現場の抵抗を最小化
- データの構造化・正本化を実現
- 将来AIにつなげられる
という三点を同時に満たせる。
フェーズ4:AI・自動化への接続―「正解を返すAI」を作るための条件
1)RAGを業務で使える状態とは何か
業務で使えるRAGとは、
「答える」だけでなく、
- 根拠が示される
- 最新版が参照される
- 誤りが検知できる
状態を指す。
そのために必要なのは、
- 文書の版管理
- 有効期限メタデータ
- 機密区分によるフィルタ
- ログとフィードバック
である。
2)RAG評価の誤解
多くのPoCでは、
「正答率」だけを見て評価する。
しかし実務では、
- 誤答が業務に与える影響
- 説明責任が果たせるか
- 判断スピードが上がったか
の方が重要だ。
つまり、
評価指標はKPIに接続すべきである。
データ資産の防衛──セキュリティとガバナンスは「資産保全」である
データが資産である以上、守る対象であることは自明だ。しかし中小企業では、セキュリティはいまだに「IT担当者の仕事」「事故が起きたら考えるもの」と捉えられがちである。この認識はAI時代において致命的だ。
攻撃者の視点に立てば、中小企業は非常に魅力的な標的である。データの価値は高いが、管理体制が脆弱で、サプライチェーンの弱点になりやすい。コスト対効果が高いのだ。
ここで失われるのは、データそのものだけではない。業務停止、信用低下、契約解除、将来のM&A評価への悪影響。これはすべて資産毀損である。
必要なのは大企業並みの統制ではない。機能する最小構成で十分だ。データ分類、最小権限のアクセス制御、バックアップ、そしてログと証跡。これらは事故対応のためだけでなく、説明責任を果たすための資産でもある。
セキュリティ投資はコストではない。Infonomicsで言えば、CVI(損失回避価値)を確保するための投資である。復旧コスト、逸失利益、信用低下の期待値を考えれば、合理性は明確になる。
データ資産は「企業価値」にどう反映されるか
自社生成データは会計上、原則として資産計上されない。しかし、評価されないことと価値がないことは違う。
M&Aや事業承継の現場では、データ整備状況は明確に見られている。データが整理されている企業はPMIが早く、シナジーが出やすい。データが属人化している企業は、再構築コストと事故確率が織り込まれる。この差は、買収価格に直結する。これが「アナログ・ディスカウント」の正体だ。
金融機関の評価軸も変わりつつある。過去の決算書だけでなく、日々の取引データ、受注・請求・在庫のリアルタイム性を見て、事業の健全性と再現性を判断する。データ資産を持つ企業は、説明可能性が高く、結果として信用力が高い。
まとめ:AI時代の勝者は、データを「資産設計」した企業である
結論は極めてシンプルだ。
AIは魔法ではない。
差別化はツールでは生まれない。
データはもはやIT資源ではない。
データは 経営資産 である。
そして、資産は設計しなければ増えない。
AI時代に問われているのは、最新技術への追随ではない。
自社のデータを、どのような資産として設計し、どの未来をつくるのか。
その問いに向き合った企業だけが、AI時代の競争を戦い抜く。
引用文献
[1] IBM, “Proprietary data, your competitive edge in generative AI.” (IBM)
[2] A. T. Kalai, “Why Language Models Hallucinate.”(RAG等による低減に言及) (OpenAI)
[3] Douglas Laney, “Infonomics”関連資料(IVI/BVI/PVI等の枠組み) (The Department of Energy’s Energy.gov)
[4] IPA, 「中小企業の情報セキュリティ対策ガイドライン」 (情報処理推進機構)
[5] 経済産業省, 「ITシステム『2025年の崖』の克服とDXの本格的な展開」(DXレポート要旨) (経済産業省)
[6] 経済産業省(英語プレス)/ IPA報告書(モダナイゼーション関連) (経済産業省)
[7] Toyota Supplier, “Green Supplier Requirements 2025.” (ts.toyotasupplier.com)







