コンテキストエンジニアリングとは何か:プロンプトの限界と生成AIの性能を決める文脈設計

 AIによる概要
AIによる概要
この記事は、生成AIの出力品質や再現性を左右する本質的な要因として、コンテキストエンジニアリング(文脈設計)の重要性を解説しています。プロンプトの書き方ではなく、AIが「どの前提・情報・制約を与えられた状態で推論しているか」が結果を支配しているという視点から、AI活用の考え方を根本的に捉え直します。あわせて、実務やAIアプリ開発において、コンテキストをどのように設計すべきかを体系的に整理しています。
- AIの性能はモデルやプロンプトではなく、文脈(コンテキスト)の設計品質によって決まる。
- コンテキストエンジニアリングは、AIの推論前提となる情報・制約・記憶を構造的に設計する技術である。
- 中核となる要素は Select / Write / Compress / Isolate の4つであり、Structureはそれらを成立させる横断原則である。
- 情報過多や文脈混濁は、Lost in the Middle やハルシネーションを引き起こす主要因である。
- 適切な文脈設計により、AIは実務で使える一貫性と再現性を発揮する。
この記事を読むことで、AIの出力が不安定になる根本原因を理解し、プロンプト改善に頼らない視点を持てるようになります。さらに、日常的なAI利用からAIアプリケーション開発まで、再現性のあるAI活用を実現するための文脈設計の考え方と実践プロセスを具体的にイメージできるようになります。
はじめに:AIの性能は「文脈設計」で決まる
生成AIの精度が劇的に向上し、多くの人が日常業務でAIを活用するようになった。しかし、次のような悩みは依然として多い。
- 指示を工夫しても思った出力にならない
- 文章は整っていても内容が浅い・誤っている
- 同じ依頼でも結果が安定しない
- AIアプリを作っても精度が頭打ちになる
これらの原因は、プロンプトの書き方にあるわけではない。
本質は AIが「どの文脈(コンテキスト)を読み取って推論しているか」 にある。
AIは世界を理解している存在ではなく、与えられたテキスト(=コンテキスト)と内部パラメータだけ で推論を行う。
そのため、文脈が不適切であれば、どれほど高性能なモデルでも誤る。
近年では、LangChain・Claude・Gemini・OpenAIによる研究や技術文脈で、
「プロンプトよりも重要なのはコンテキストの設計である」
という視点が急速に普及している(出典:LangChain Blog / Anthropic ほか)。
つまり、AIの出力は“文脈設計の質”に支配されている。
しかし、その重要性に反して、コンテキスト設計の原理やプロセスは広く認知されていない。
この視点が欠けたままでは、プロンプトを改善しても安定性は得られないし、ビジネス利用に耐えるAIアプリケーションを構築することは難しい。
本稿では、この“見えないインフラ”とも言えるコンテキストエンジニアリングを体系的に整理し、その実践プロセスとコンテキストエンジニアリングにおける良い例と悪い例を解説する。
コンテキストエンジニアリングとは何か(定義と本質)
コンテキストエンジニアリングとは、
「AIが推論するために必要な前提条件・情報・制約を、最適な構造で設計する技術」
である。
AIを正しく動かすには、以下の要素をすべて人間側が設計する必要がある。
- どの情報を渡すか(Select)
- どの順番で渡すか
- どの形式で渡すか(Structure)
- どの粒度に整理するか(Compress)
- セッション内の「記憶」をどう管理するか(Write)
- 推論環境をどう分離するか(Isolate)
プロンプトとコンテキストの違い
| 要素 | プロンプト | コンテキスト |
|---|---|---|
| 役割 | 操作説明 | 作業環境 |
| 範囲 | 単一ターンの指示 | 外部知識・前提・制約の全体 |
| 肝となる課題 | 文言表現 | 構造化・情報設計・検索戦略 |
| 寿命 | その場限り | エージェント全体の推論を支配 |
プロンプトは“操作説明”にすぎない。
しかしコンテキストは、AIが「何を知った状態で推論するか」という思考の前提そのものである。
ビジネスにおける重要性
コンテキスト設計が不十分な場合、次のような問題が起きる。
- 誤った仕様を参照する
- 重要情報を読み落とす
- 検索でノイズを拾う
- 特定ステークホルダーの意図を誤解する
- 設計書・仕様書との整合性が取れない
逆に、文脈設計を整えると、AIは“実務で使えるレベルの一貫性”を発揮し始める。
コンテキストエンジニアリングの定義を分解すると、本質は以下の3つに集約される。
(1) コンテキストは“単なる情報”ではなく“認知環境”である
AIは、与えられたテキストを「世界そのもの」として扱う。
そのため、次のような整理が必要になる。
- どこまでをAIの“世界”とするか(範囲)
- どの情報を重要と扱わせるか(優先度)
- どの順番で理解させるか(構造)
- どの形式が理解しやすいか(フォーマット)
これはもはや“文章の書き方”ではなく、認知環境の設計に近い。
(2) コンテキストは“固定テキスト”ではなく“動的資源”である
AIアプリケーションでは、状況や入力内容に応じて毎回必要な文脈が変わる。
そのため、事前に固定したプロンプトを置いておくだけでは十分ではない。
必要なのは、以下を動的に生成する仕組みである。
- 必要な情報だけを選び出す(Select)
- 過去ログから要点だけを残す(Compress)
- 新しい知識を蓄積する(Write)
- 情報を混濁させないため文脈を分離する(Isolate)
これらはすべてコンテキストエンジニアリングの守備範囲となる。
(3) コンテキストは“単一ターン”ではなく“セッション全体”を扱う
プロンプトエンジニアリングは、単一の指示をどう書くかという点の最適化に近い。
一方、コンテキストエンジニアリングは、一連の対話・プロセス全体をどう構築するかという線・面の最適化である。
AIアプリではさらに、
- 過去タスクの記録
- 外部ドキュメント
- RAG検索結果
- メモリ管理まで扱う必要がある。
つまり、コンテキストエンジニアリングは「AIが動くOS」を組み立てる仕事と言える。
プロンプトエンジニアリングでは限界がある物理制約と経済制約
プロンプト改善を繰り返しても結果が安定しないのは、AIモデルの構造的特性による。
コンテキストウィンドウには限界がある
AIは一度に読める情報量(=コンテキストウィンドウ)が限られている。
200万トークン対応モデルでも、“無条件で大量情報を渡せばよい”わけではない。
- 重要情報が埋もれる
- 不要情報の比率が高くなる
- Attention が分散し特定箇所を見落とす
- 中間部分が理解されにくくなる(Lost-in-the-Middle)
これはプロンプトでは解決できない。
情報の選別(Select)が必須になる理由はここにある。
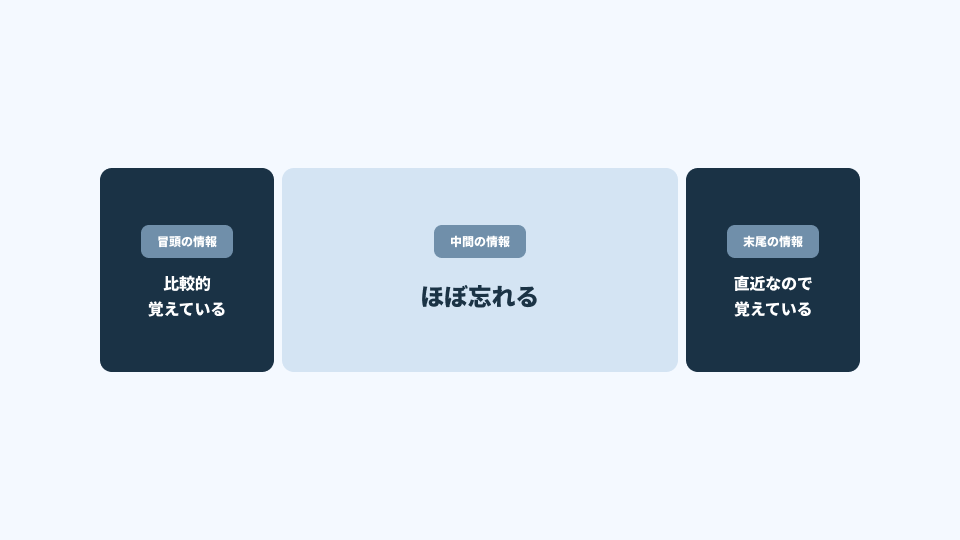
Lost in the Middle(中間情報の消失問題)
AIは、文章の中間部分を軽視しやすい性質がある。
- 冒頭の情報:比較的覚えている
- 末尾の情報:直近なので覚えている
- 中間の情報:ほぼ忘れる
これは注意機構の構造に起因し、長文になるほど顕著に現れる。
例:
- セクション2が最重要なのに、1と3ばかり参照する
- FAQの中盤が無視される
- 仕様書の重要パートが読まれない
この現象を回避するには、文脈の再配置・圧縮・強調といったコンテキストエンジニアリングのテクニックが不可欠である。
コンテキスト汚染(ノイズ混入)
複数の情報源が混在することで起きる。
- 古い仕様と新しい仕様が混在
- メール文体のまま文章が混じる
- 会話ログが残っている
- 曖昧な記述が多い
ノイズが混入すると、AIは「正しい情報」ではなく「出現頻度の多い情報」に引っ張られやすい。
プロンプトの工夫では防げない。
必要なのは 文脈の純化(Structure / Compress) である。
推論コストの増大と実務的限界
大量の文脈を渡すと以下が発生する。
- 推論時間(応答速度)が長くなる
- APIコストが増大する
- 非効率な設計になる
特に企業においては、AI利用コスト最適化の観点からも文脈の引き締めが不可欠となる。
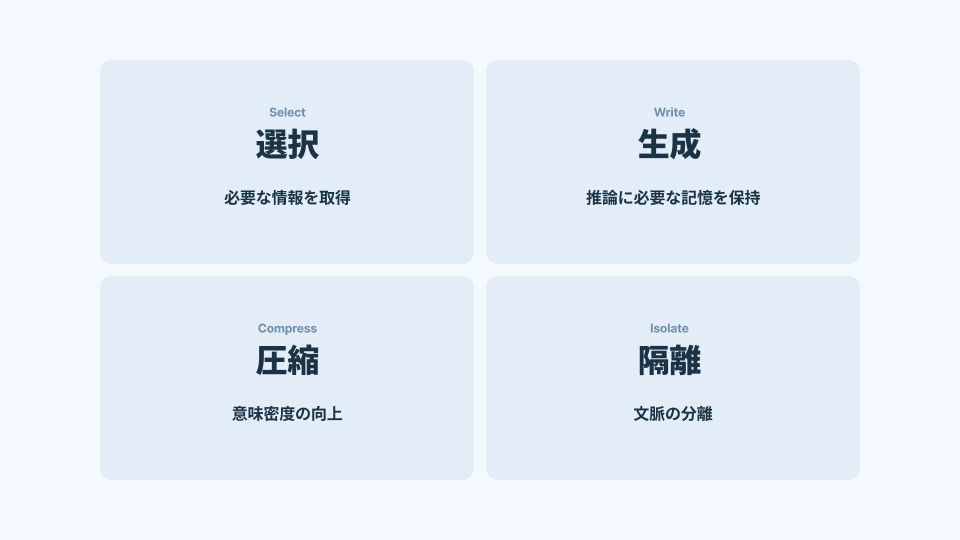
コンテキストエンジニアリングの4要素
本稿では中核を4要素(Select / Write / Compress / Isolate)とし、Structureはそれらを成立させる横断原則として扱う。
文脈設計の核心を成すのは、以下の4つの要素である。
- Select:必要な情報を“選ぶ”
- Write:推論に必要な“記憶”を適切に保持する
- Compress:情報を“意味を保ったまま圧縮する”
- Isolate:文脈の混濁を防ぐため“分離する”
以下、ビジネス実務の文脈に合わせ、できる限り具体的に体系化する。
Select:必要な情報を取得する(検索戦略の設計)
Select の質が低いと、AIは誤った前提で推論し、結果は安定しない。
ここでは、実務で最も効果の高い3つの技術を扱う。
(1)意味単位でのチャンク化(Context-aware Chunking)
仕様書やナレッジを AI で扱う場合、
文字数で分割するのは最悪の方法 である。
見出し・段落構造・論理構造を維持した分割が必須。
単純な固定長チャンク
# 悪い例:文字数だけで無機質に分割
chunks = [text[i:i+500] for i in range(0, len(text), 500)]
→ コンテキストが中途半端に切れ、意味が失われる。
見出し単位でチャンク化(Python)
import re
def chunk_by_heading(text):
# H1〜H3見出しを基準に分割する
pattern = r"(#+ .+)"
sections = re.split(pattern, text)
chunks = []
current = ""
for part in sections:
if part.startswith("#"):
if current:
chunks.append(current)
current = part + "\\n"
else:
current += part
if current:
chunks.append(current)
return chunks
→ 文書の意味構造を保ったまま分割できる。
(2)ハイブリッド検索(Vector × Keyword)
単純なベクトル検索は意味理解が得意だが、“固有名詞・型番・法令番号”には弱い。
キーワード検索は厳密一致に強いが、意味を捉えきれない。
最適なのは ベクトル検索 × キーワード検索の組み合わせ である。
ハイブリッド検索(LlamaIndexなど)
from llama_index.core import VectorStoreIndex, SimpleKeywordTableIndex
vector_idx = VectorStoreIndex.from_documents(docs)
keyword_idx = SimpleKeywordTableIndex.from_documents(docs)
def hybrid_search(query):
v_results = vector_idx.query(query)
k_results = keyword_idx.query(query)
return rerank(query, v_results + k_results)
→ 「意味 × 文字列」を同時に満たすため精度が安定する。
(3)リランキング(Cross-Encoder)
検索結果をそのまま使うのではなく、「どの文書がタスクに最も関連が高いか」を再評価し並べ替える工程。
検索後の「並び順」が AI の推論に大きく影響する。
リランキングの考え方
# ベクトル検索で上位20件を取得
initial_docs = vector_search(query, top_k=20)
# Cross-Encoderでスコア付けして再ソート
reranked = sorted(
initial_docs,
key=lambda d: cross_encoder_score(query, d.text),
reverse=True
)
top_context = reranked[:5] # 上位5件だけ使う
→ AIに渡す文脈の中でも「何を上位に置くか」で結果が変わる。
Write:外部記憶の設計(短期・長期メモリ)
LLMはステートレスであり、本来“記憶”を持たない。
そのため、必要な前提条件や過去の情報は外部に保持し、再利用できる形にする。
代表的な記憶の方法は以下の3つである。
(1)Scratchpad(一時的な思考のメモ帳)
推論途中の計算や論点整理を保存する。
Scratchpad構造(Markdown)
## Scratchpad
- 課題:〇〇を判定せよ
- 仮説1:〜
- 証拠:〜
AIに渡すときは次のようにする。
<scratchpad>
過去の結論:〜
現在の検討ポイント:〜
</scratchpad>
→ Claude や Gemini は XML 構造を非常に高速に理解する。
(2)長期記憶(Semantic / Episodic)
- Semantic Memory:事実、手順、仕様
- Episodic Memory:過去の失敗例、成功例、QAログ
これらを区別すると、検索効率と再現性が大幅に向上する。
(3)Reflection(自己反省ループ)
毎回ゼロから考えさせるのではなく、学習可能な構造にする。
Reflectionプロンプト例
<reflection>
<task>今回の出力の改善点を3つ抽出せよ</task>
<rules>
<rule>曖昧な表現を避ける</rule>
<rule>事実と推論を分離する</rule>
</rules>
</reflection>
Compress:意味を保ったまま圧縮する
重要なのは 「情報量」ではなく「意味密度」 である。
情報量が多いほどAIは混乱しやすい。そのため「圧縮(Compress)」は、コンテキスト設計の中でも最も投資対効果の高い領域である。
(1)プログレッシブ要約(長い履歴を抽象化)
Before:会話ログそのまま
User: 昨日の議事録をまとめて…
AI: …
User: あとこの前の仕様変更も反映して…
AI: …
→ Lost in the Middle が発生する。
After:前提情報へ抽象化
<context_history>
<user_intent>議事録を短く整理し、仕様変更に反映することを求めている。</user_intent>
<past_decisions>
<decision>議事録の構造は要約形式に統一</decision>
<decision>仕様変更の記述は最新版へ集約</decision>
</past_decisions>
</context_history>
(2)段落フィルタリング(不要情報を除去)
def filter_paragraphs(paragraphs, query):
return [
p for p in paragraphs
if llm_check_relevance(query, p) > 0.7
]
→ 関連性の低い文章を削るだけで、AIの精度は大幅に改善される。
(3)Map → Zoom-in(階層構造)
コードベース、仕様書など大型ドキュメントではまず“全体構造(Map)”だけを渡し、“必要箇所(Zoom-in)”だけにする方式が有効。
コードベースの地図
<code_map>
<file name="auth.py" role="認証処理"/>
<file name="db.py" role="DBコネクション"/>
<file name="routes/user.py" role="ユーザーAPI"/>
</code_map>
この後、必要なファイルだけ個別にロードする。
Isolate:文脈を分離する(混濁防止)
複雑なタスクを単一の文脈で処理すると、
指示や情報が混濁し、精度が低下する。
そこで、文脈を意図的に分離する。
(1) マルチエージェント
- 検索担当
- 推論担当
- コード生成担当
- レビュー担当
など役割ごとに文脈を分離し、
上位エージェントが調整する。
(2) サンドボックス実行
計算処理・コード実行はモデル外で行い、
結果だけを要約して渡す。
5. 実践プロセス:コンテキスト設計はどのように行うのか
ここからは、コンテキストエンジニアリングを実務で実践する際のプロセスを体系化する。
特に「何を、どの順番で、どのように行うと品質が安定するのか」を明確にすることが目的である。
以下は、AIアプリケーション開発でも日常のChatGPT利用でも共通するプロセスである。
- タスク定義
- 必要情報の抽出(Select)
- 情報の構造化(Structure)
- 記憶の管理(Write)
- 意味を保った圧縮(Compress)
- 品質評価(Precision / Recall)
- 改善
ビジネスユースでは Select・Structure・Compress が特に重要 であり、この3つの質が AI の安定性を決める。

Step1:タスク定義(What / Why / Constraints の明確化)
コンテキスト設計は、タスク定義から始まる。
これは単なる要件整理ではなく、
「AIがどの判断を下し、どの出力形式を満たせば成功と見なせるか」
を明確化する作業である。
ここで曖昧なまま進むと、SelectやCompressの段階で何を残すべきかが判断できず、システム全体が不安定になる。
まず、以下を明確にする。
- What(何を実行するか)
- Why(何のために実行するか)
- Constraints(制約条件)
- Output format(想定出力形式)
Step2:Select(必要情報の抽出)
タスクの要求を踏まえ、必要な外部情報・内部情報を選定する。
代表的な情報源は次の通りである。
- 仕様書
- 手順書
- 過去の質問や回答
- FAQ
- ソースコード
- 会話履歴(ただし要約必須)
- ドキュメントベース(RAG)
この工程では、
“そのタスクに必要な情報のみを抽出できるかどうか”
が最重要ポイントである。
情報の選別精度が低いと、次のプロセス(構造化・圧縮)で問題が連鎖的に発生する。
Step3:情報の構造化(Structure)
AIに渡す情報は「構造」が命である。
特に次の2点が極めて重要である。
(1) フォーマットを揃える
複数のデータソースを統合する場合、
メール文体、コード、箇条書き、PDF抽出テキストが混在するとAIは混乱する。
最適なのは以下の形式:
- XMLタグ(Claude系に最適)
- JSON(機械可読性が高い)
- Markdown(階層構造を明示できる)
これらは、AIが情報の境界を認識しやすいからである。
(2) 重要情報を先頭に置く
LLMには「先頭バイアス」「直近バイアス」が存在する。
重要情報を上部に配置し、不要情報を下部に配置するだけで精度が変わる。
Step4:Write(記憶管理:短期・長期メモリ)
Select で選んだ情報のうち、
「繰り返し使用する情報」 を長期記憶として保存する。
例:
- FAQの回答パターン
- 製品仕様
- よく発生する問題
- コードスニペット
- 決済ルール
Scratchpad・Reflection による「一時的な推論情報」もここで管理する。
この工程が弱いと、AIは毎回ゼロから推論し、再現性が低下する。
Step5:Compress(情報圧縮)
圧縮は「情報を削ること」ではなく
“意味を保ったまま密度を高める工程”
と定義される。
代表的な手法は次の通り。
- 過去ログの抽象化
- 文書の箇条書き化
- 不要段落の除去
- Map→Zoom-in 方式による階層化
コンテキストウィンドウの制約を前提に、
最小量で最大の意味を伝える
ことが求められる。
Step6:評価(Precision / Recall)
コンテキストの品質は、感覚ではなく定量的に評価する必要がある。
Context Precision(適合率)
AIが実際に回答に使用した情報の割合。
ノイズが多いと precision が下がる。
Context Recall(再現率)
回答に必要だった情報のうち、コンテキスト内に含まれていた割合。
不足があると recall が下がり、ハルシネーションが発生する。
Step7:改善(Feedback loop)
Select・Compress の改善は継続的であるべきであり、
「一度作って終わり」ではない。
特に、自社AIアプリでは継続運用が前提となるため、改善サイクルを組み込むことが必須である。
エラー事例をもとに、検索ロジック・構造化方法・圧縮方法を改善する。
影響度の高いプロセスにおける Good / Bad パターン
ここから、実務で最も改善効果が高い領域に絞り、
Good / Bad の例を示す。
Select(情報選択) の Good / Bad
Bad例:とりあえず全部入れる
多くの失敗はここから始まる。
例:
- 仕様書(100ページ)を丸ごと投げる
- 過去の会話ログをすべて残す
- 部署から来た資料すべてを統合してしまう
結果として「情報過多」になり、AIは本質情報を見失う。
発生する問題:
- Lost in the Middle
- 推論ノイズ
- ハルシネーションの増加
- トークンコストが激増
- 実行速度低下
Good例:タスクに必要な、意味単位のチャンクだけを選ぶ
正しいプロセスは以下である。
- 文書を意味単位(セクション・段落)でチャンク化
- タスクに関連するチャンクだけを検索(RAG)
- リランキングで重要度順に並べ替える
- 先頭に“最重要チャンク”を置く
Structure (構造化)の Good / Bad
Bad例:構造がバラバラ
例:
- メール文のまま貼り付ける
- コードブロックと自然文が入り交じる
- 箇条書きと表記ゆれした文章が混在
この仕様を確認して回答してください。
・旧仕様:〜〜〜〜〜
・新仕様:〜〜〜〜〜
(メール本文)
…中略…
function a() { ... }
→ AI はどこが重要なのかわからない
Good例:Claude/Gemini向け XML構造
<context>
<task>
旧仕様と新仕様の差分を3点にまとめて説明せよ
</task>
<rules>
<rule>理由を添えて説明すること</rule>
<rule>専門用語を使いすぎない</rule>
</rules>
<reference>
<old_spec> ... </old_spec>
<new_spec> ... </new_spec>
</reference>
</context>
→ 一貫した構造により、AIは「役割・ルール・前提」を正確に解釈する。
Compress(圧縮) の Good / Bad
Bad例:履歴をそのまま渡す
ユーザー:昨日はどうでしたか?
AI:良かったです。
ユーザー:じゃあ今日は?
AI:…
→ 情報量は多いが意味密度が低く、誤解が発生する。
Good例:要約して意味を残す
例:
- 「ユーザーの意図」だけ抽出
- 前回回答の要点だけ残す
- 過去ログは抽象化し“前提”として再構成する
summary = llm("以下を50字以内で要約し、ユーザーの意図を抽出せよ:\\n" + full_history)
context = f"""
<context_summary>
<intent>{summary['intent']}</intent>
<constraints>{summary['constraints']}</constraints>
</context_summary>
"""
→ 情報量は減るが、意味は増える状態をつくれる。
まとめ:AI活用の本質は「文脈を設計する力」である
AIの性能は、モデルそのものの賢さよりも、
「どの文脈を読ませて推論させたか」 に依存する。
プロンプトは操作説明にすぎないが、
コンテキストは 推論の前提・制約・背景知識・記憶状態 をすべて規定する。
つまり、文脈設計は AI の“認知状態”そのものをつくり出す行為である。
本稿で示したように、AIを活用するうえで最も重要なのは
「どんな文脈を与えるか」である。
- 情報を絞り込む(Select)
- AIが理解しやすい形に整える(Structure)
- 意味を保ったまま圧縮する(Compress)
- 再利用できるよう知識を蓄える(Write)
- 混濁を避けるため文脈を分離する(Isolate)
これらの技術を適切に実践することで、
AIの出力品質は劇的に安定し、業務への適用範囲も拡大する。
逆に、文脈設計が甘ければ、
どれほど高性能なモデルを使っても結果は安定しない。
AI活用の「鍵」はプロンプトではなく、
コンテキストエンジニアリングという“認知のインフラ設計”にある。
引用文献
コンテキストエンジニアリングの基礎概念
- LangChain Blog – Context Engineering for Agents
- Nearform – Beyond Prompt Engineering: the shift to Context Engineering
- Elasticsearch Labs – What is Context Engineering?
- Anthropic – Effective Context Engineering for AI Agents
情報検索(RAG / Select)関連
- Transform Results with the Right RAG Strategy(Medium)
- Elasticsearch Labs – Maximal Marginal Relevance
- Combining State-of-the-Art Models with MMR for Summarization
圧縮(Compress)関連
- LangChain – Contextual Compression Retriever
- LlamaIndex – Contextual Compression 解説記事
長期記憶(Write)関連
- Memory Architecture(LangChain Docs)
- Reflection(LLM 自己改善ループ)関連文献
構造化・フォーマット(Structure)
- Claude Docs – XML Tagging for Prompt Structure
- Kyle’s Blog – Prompt and Context Engineering with XML
評価指標(Context Precision / Recall)
- Ragas Documentation – Context Precision
- Medium – RAG Evaluation Simplified
実装最適化(キャッシュ・パフォーマンス)
- Google – Context Caching Documentation
- PromptHub – Prompt Caching 解説







