AI検索(RAG)がビジネスをどう変えていくか― 検索行為の再定義と知的資本の再設計 ―

 AIによる概要
AIによる概要
この記事は、AI検索(RAG+セマンティック検索)の登場によって、検索が「文字列照合」から「意味の想起」へ変わり、企業の業務スピードや意思決定の仕組みそのものが作り替わり始めていることを解説しています。単に“検索が便利になる”のではなく、知識が人に固定される構造を、仕組み側へ移すことで、組織の知的資本の流通を変える点が主題です。
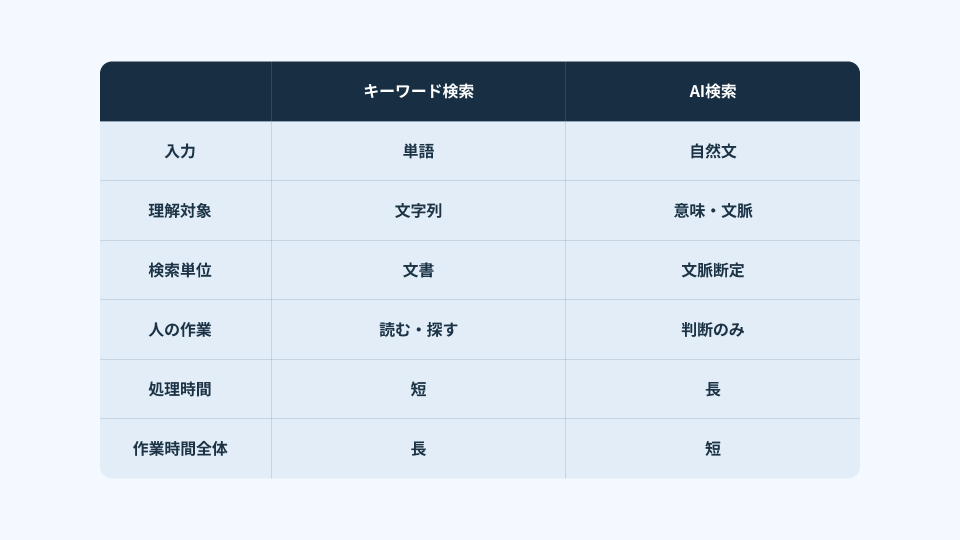
- AI検索は「探す」と「読む」を同時に行い、断片を文脈として再構成して返す。
- キーワード検索とAI検索は競合ではなく補完で、所在探索は前者、意味探索は後者が強い。
- AI検索は遅く見えても、判断に至るまでの総時間(探し直し・聞きに行く・合意形成)を圧縮する。
- 最も効くのは曖昧・文脈依存・横断的な問いで、ナレッジ、ITサポート、CS、提案書作成、現場安全、経営判断に波及する。
- 導入成否は技術より「問いの配線」で決まり、最初は業務を絞ってログから未整理な業務を可視化し、運用で精度と統制を育てる。
読者は、AI検索が「速い検索」ではなく判断の前段インフラである理由が分かり、キーワード検索とどう棲み分けるべきかを整理できます。さらに、導入時にどの業務から始めるべきか、どんな問いをAI検索に流す設計にすると成果が出るかが見えるようになり、PoC〜運用の進め方を現実的に描けるようになります。
AI検索(RAG + Semantic Search)の登場は、人の検索行為そのものを変え始めている
AI検索(RAG + Semantic Search)の登場は、検索技術の延長線上にある改善ではない。
それは、人が情報を探し、思い出し、理解し、判断に至るまでの一連の行為そのものを再設計し始めている。
企業活動において「検索」は、意思決定や実行の“前段”に位置する。だからこそ、検索そのものはしばしば「補助機能」と見なされ、改善の優先順位が上がりにくい。ところが現在、その前提が揺らいでいる。理由はシンプルで、企業の情報環境が変わったからだ。
現在の企業環境では、業務データの多くが非構造化データとして蓄積されている。メール、チャットログ、契約書、仕様書、顧客対応履歴など、重要な判断材料が“文章の塊”として増え続ける一方で、それらを横断的に使うための設計は追いつきにくい。【1】
この状況では、次のような現象が起きる。
情報は存在しているのに、見つからない。
見つからないから、人に聞く。
結果として、知識が人に固定され、組織として再利用されない。
ここで本質的なのは、「情報がない」のではなく「情報へ到達できない」という摩擦が、日々の業務速度を確実に落としている点にある。検索が遅いのではない。検索に失敗した後の“迂回路”が高コストなのである(探し直す、聞きに行く、会議で確認する、判断が遅れる、手戻りが増える)。
AI検索は、この“迂回路”を短絡させる。
従来のキーワード検索が「文字列の一致」を前提としていたのに対し、AI検索は 意味・文脈・背景 を扱うことを前提に設計されている。言い換えるなら、検索を「文字列照合」から「意味の想起」に近づける試みである。
そしてこの変化は、単なる利便性の向上に留まらない。
組織の知的資本が、人ではなく仕組みによって流通する方向へ、企業の情報設計を押し進める。これが、AI検索を「トレンド」ではなく「スタンダード」と捉えるべき理由である。

AI検索とは何か ─ 従来検索との構造的な違い
AI検索を正しく理解するには、まず「従来のキーワード検索が何を前提に成立してきたか」を押さえる必要がある。ここを曖昧にしたまま議論すると、AI検索の評価軸が「速い/遅い」「当たる/外れる」といった表層比較に寄ってしまい、導入判断を誤りやすい。
キーワード検索が前提としている世界
従来の企業内検索やWeb検索の多くは、逆列挙インデックス(Inverted Index)やTF-IDFといった仕組みに依存してきた。これは、ユーザーが入力した検索語句と、文書内の単語が“字面として一致するか”を機械的に判定するアプローチである。【2】
この方式が高い効果を発揮するのは、次の条件が揃っている場合だ。
- 探す対象が明確である(ファイル名、型番、契約番号など)
- 正しい名称・表記を知っている
- 文書単位で情報が完結している(見れば答えが書いてある)
実務では、たとえば以下のような検索が該当する。
- 「2024年3月締結 業務委託契約書」
- 「〇〇社向け見積書 最終版」
- 「製品A 型番1234 操作マニュアル」
これらは「何を探しているか」が明確で、検索の目的も「所在の特定」に近い。
この領域において、キーワード検索は今後も有効であり続ける。AI検索が代替するというより、役割が違う。
問題は、ビジネスの現場で頻出する検索の多くが、実はこの前提を満たしていないことだ。
キーワード検索が苦手とする“現実の検索”
現実の業務では、「検索したい対象はあるが、検索語に落とし込めない」問いが大量に発生する。たとえば次のようなものだ。
- 「PCの調子が悪い。前にも似た事象があったはずだが、どれだ?」
- 「社長が先月言及していた“新しいプロジェクト”って、結局どういう整理だったか?」
- 「この契約、過去に例外対応したことはなかったか?」
- 「この施策、以前なぜ却下されたのか?誰が何を懸念していたのか?」
キーワード検索は、こうした問いに対して構造的な弱点を持つ。
第一に、表記揺れ(シノニム)に弱い。ユーザーが「PCの調子が悪い」と検索しても、文書側に「パソコンの不具合」「コンピュータの故障」と書かれていれば一致せず、ヒットしないことがある。【3】
第二に、文脈理解ができない。「社長が先月言及した新しいプロジェクト」のような、エピソード記憶や背景依存のクエリを解釈できない。【4】
第三に、仮にヒットしても、情報が断片化して提示される。結果は文書のリストであり、ユーザーが開いて該当箇所を探し、読み、つなぎ合わせる必要がある。ここに多大な認知負荷と時間が発生する。【5】
つまり、キーワード検索が苦手なのは「検索精度」だけではない。
“探す→読む→理解する”を人間側に丸投げする設計そのものが、情報量と業務スピードが上がった現在の企業環境と噛み合わなくなっている。
AI検索がやっていること ─「探す」と「読む」を同時に行う
AI検索は、この断絶を埋めるために設計されている。
定義としては、「ユーザー入力 → ベクトル検索で関連情報を取得 → LLMで整形・推論して返す」という一連のプロセスを実行するシステムを指す。【6】
ここで重要なのは、AI検索が“検索結果の羅列”を返す設計ではない点だ。AI検索は、ユーザーの問いに対して次の処理をまとめて実行する。
- 質問文を意味として捉える(何を知りたいのか/何が前提か)
- 概念的に関連する情報を、複数文書から引き当てる
- 断片を並べるのではなく、文脈として整理して提示する
- 参照元を示し、判断可能な形に整える(※ここがRAGの重要点)
従来の検索が「候補の提示」までで止まっていたのに対し、AI検索は “理解の前処理” を引き受ける。
その結果、ユーザーは「読むこと」ではなく「判断すること」に集中できる。
この違いは、UIの改善というより、業務プロセスの再配分である。
つまりAI検索は、検索ツールであると同時に、判断支援のための前段インフラになり得る。
なぜAI検索はキーワード検索より処理に時間がかかるのか
AI検索は、体感としてキーワード検索より遅くなりやすい。これは実装の未熟さというより、実行している処理が別物だからである。
キーワード検索の中核は、インデックス参照と単語一致判定であり、処理としては軽い。一方、AI検索は少なくとも次の工程を含む。
- 質問文の意味解析(Embedding生成)
- ベクトル空間での類似検索(コサイン類似度/ユークリッド距離等)
- 必要に応じた再ランキング
- LLMによる要約・統合・生成(=“読む”工程の肩代わり)
セマンティック検索では、テキストを高次元の数値ベクトルとして表現し、意味が近いものほど幾何学的に近く配置する。類似度検索は、質問文も同様にベクトル化し、ドキュメント側ベクトルとの距離(コサイン類似度やユークリッド距離)から関連情報を抽出する。【7】
RAGはそこに、検索で得た情報をコンテキストとしてLLMに渡し、知識のカットオフやハルシネーションのリスクを下げつつ、根拠に基づく回答生成を行う枠組みである。【8】
つまりAI検索は、「探す」だけでなく「読む」「要約する」「整える」までを同時に行う。その分、レスポンスが数秒遅くなるのは自然な帰結だ。
ただし、業務で重要なのは“検索ボタンを押してから返ってくるまでの秒数”ではない。
本当に短縮すべきは、次の時間である。
- 候補を開いて探し当てる時間
- 複数文書を読み比べて状況を復元する時間
- 前提を確認し、判断材料を揃える時間
- 誰かに聞きに行き、説明し直し、合意を取る時間
AI検索の価値は、検索の1〜3秒を削ることではなく、判断に至るまでの“総時間”を圧縮することにある。
この視点に立つと、「AI検索は遅いから使われない」という直感は、業務全体の時間配分を見落としている。
キーワード検索とAI検索は競合しない
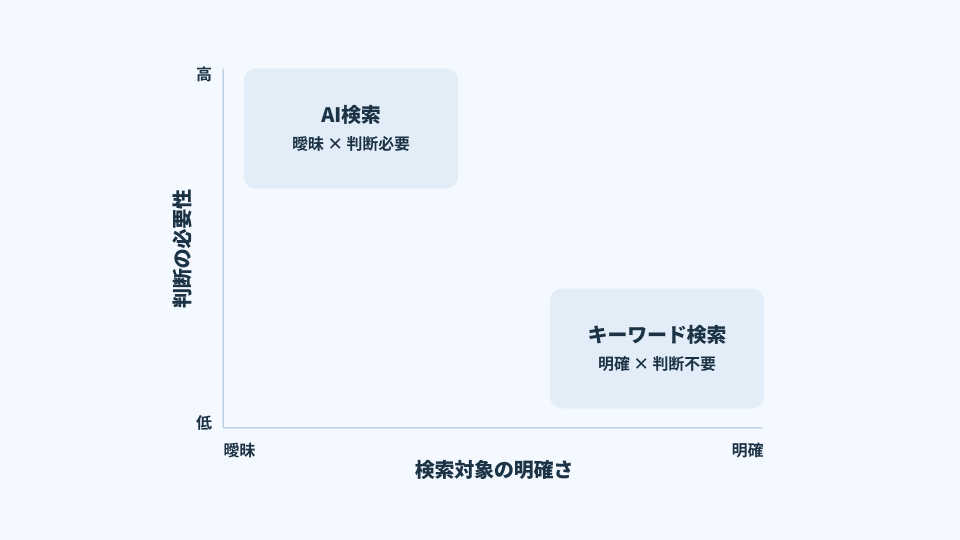
AI検索の導入検討で、最初に整理しておくべき論点は「どちらが優れているか」ではない。実務における問いは、検索という同じ単語で括っていても、必要としている処理が異なるからだ。キーワード検索は「同じ言葉を含む場所を速く見つける」ことに強く、AI検索は「似た意味を含む断片を集め、文脈として再構成する」ことに強い。両者は競合関係というより、業務プロセスの別地点を支える補完関係にある。
では、業務側でどう線引きすべきか。判断の起点は、検索対象の“明確さ”ではなく、問いが要求している行為である。言い換えると、次のどちらかだ。
- 所在を特定したい(どこにあるか)
- 判断材料を揃えたい(なぜそうなったか、どう解釈すべきか)
前者はキーワード検索が最短経路になりやすい。後者はAI検索が、業務時間を実質的に短縮する。 多くの企業が詰まるのは、技術選定よりも先に、「AI検索に投げる問い」を業務として定義できていないことだ。AI検索を「遅い」「微妙だ」「結局使わない」と言われるケースの多くは、AI検索が不得意な領域(識別子で一意に探せる検索)までAI検索に寄せてしまい、体験価値を毀損している。逆に、AI検索が本領を発揮する領域(曖昧・文脈依存・横断的)で使わせる設計ができていない。
キーワード検索が最適となる業務構造
キーワード検索が最も強いのは、識別子が明確で、検索結果がほぼ一意になる領域である。ファイル名・型番・契約番号・注文番号などが存在し、表記揺れが少なく、探す側が「正しい名称」を把握している場合だ。従来型検索は、逆列挙インデックスやTF-IDFを中心に「字面の一致」を高速に判定する設計であり、この条件では非常に合理的に動作する。【5】
実務で言えば、次のような検索である。
- 特定の契約書・見積書・請求書を探したい
- 特定のマニュアル(型番指定)を探したい
- 特定の稟議書(案件名・案件番号)を探したい
このときユーザーは、文書の内容を理解したいというより、まず「そのファイルを開ける状態にしたい」。ここではAI検索が生成する要約や統合回答は必須ではなく、むしろレスポンスの追加コストが体験を悪化させる可能性すらある。
重要なのは、速く、軽く、確実にヒットするキーワード検索がこの領域で「今後も残る」ことを前提に、業務設計を行うことだ。AI検索は万能ツールではない。万能化させようとすると、現場の納得感を失う。
AI検索が不可欠になる業務構造
AI検索が必要になるのは、問いの本質が「ファイルを見つけたい」ではなく、「判断の背景を復元したい」領域である。ここでは、適切な検索語が存在しない、もしくは存在してもユーザーがそれを知らない。
たとえば次のような問いは、現場で頻繁に発生する。
- 以前似た障害があった気がするが、どう対応したか
- 過去に例外対応した契約条件があるか
- 施策が却下された理由は何だったか(誰が何を懸念したか)
- 同じような顧客要望への返答例(言い回し・判断の仕方)を探したい
これらは「正しい言葉」を当てにいく検索ではない。むしろ、あいまいな記憶を足がかりに、関連する断片を集めて状況を復元する行為である。従来型検索が苦手とするのは、この“復元”の工程だ。表記揺れ(シノニム)に弱く、文脈理解ができず、結果が断片(URLの羅列)として提示されるため、ユーザーに認知負荷が集中する。【4】
AI検索は、この断絶を「意味」によって跨ぐ。質問文をEmbeddingでベクトル化し、データベース内のドキュメントベクトルとの類似度(コサイン類似度やユークリッド距離)を計算して、概念的に近い情報を抽出できる。【1】 ここで得た断片をコンテキストとしてLLMに渡し、読み手が判断できる形に整形して返す、というのがAI検索の基本動作である。【1】
要するに、AI検索が得意なのは「検索」ではなく、検索に付随して本来人間が行っていた「読む」「つなぐ」「要点化する」を引き受ける点である。
検索手段を“機能”ではなく“業務”で切り替える
共存設計で最も重要なのは、UIとして「キーワード検索とAI検索が両方ある」状態を作ることではない。業務として、どちらを使うべきかが自然に決まる状態を作ることである。
ここで鍵になるのは、検索の目的を明確に言語化することだ。たとえば社内の検索ニーズは、大きく次の二種類に分けられる。
- 所在探索:特定ファイル・特定データの場所を見つける
- 意味探索:判断材料・背景・過去事例・論点を引き出す
この二分類が合意できれば、キーワード検索は前者の最短経路として残し、AI検索は後者のボトルネック解消として導入できる。逆に、この分類がないと、AI検索に「所在探索」をやらせて遅いと言われ、キーワード検索に「意味探索」をやらせて見つからず、結局人に聞く、という“最悪の三重構造”に戻ってしまう。
繰り返しになるが、AI検索導入の成否は、技術の先進性ではなく、問いの配線(どの問いをどこに流すか)で決まる。
圧倒的にAI検索が効く業務シーン
AI検索の価値が最も分かりやすく立ち上がるのは、「情報はあるのに探せない」という摩擦が、業務コストの中心になっている領域である。ここでは、単にユースケースを列挙するのではなく、「どのような問いが投げられ」「何が返ると業務が前に進むのか」という観点で掘り下げる。
社内ナレッジ検索(総務・人事・管理部門)
総務・人事・経理といったバックオフィスには、問い合わせが集中する。制度や手続きは文書化されているにもかかわらず、問い合わせが減らない理由は明確だ。規程は“読むため”には整っていても、“問いに答えるため”には整っていない。条件分岐が多く、例外も多く、前提が文脈依存であるため、検索語を当てるだけでは到達できない。
たとえば次のような問いがある。
- 育休から復帰する際の必要手続きは何か(期限や提出先も含めて)
- 出張規程の例外(グリーン車・前泊など)はどの条件で認められるか
- 交通費精算で領収書が出ないケースはどう扱うべきか
AI検索の価値は、規程文書そのものを返すことではない。規程、補足資料、過去の運用例(メールやチャットの判断ログ)を横断し、「条件→結論→根拠→手順」の順に整理して返す点にある。これにより、問い合わせ側は“規程を読む”作業から解放され、担当者側は“同じ説明を繰り返す”負担から解放される。
この領域での導入効果は、問い合わせ削減だけではない。制度運用が人に依存している状態(属人運用)から、根拠が残る状態(統制運用)へ移行する。結果として、監査対応や引継ぎの品質も上がる。
情報システム・ITサポート(ヘルプデスク、社内IT)
IT部門への問い合わせは、「調べれば分かるが、どこを見ればよいか分からない」が大半である。マニュアルは存在しても、現場は忙しく、読み込む余裕がない。また、障害は“似て非なる”ケースが多く、過去ログを横断して状況を復元する必要がある。
典型的な問いは次のようになる。
- VPNが繋がらないときの切り分け手順は何か(自分の環境で何を確認するか)
- このエラーコードは過去に何が原因で、どう直したか
- 特定アプリが遅いが、ネットワーク側で見てよいか、それとも端末側か
AI検索が強いのは、マニュアル、FAQ、過去の障害対応記録、チケット履歴を横断し、「まず何を確認し、次に何を疑うべきか」という切り分けを、根拠と共に提示できる点である。重要なのは、これが一次対応の自動化に直結することだ。夜間や担当者不在でも、同等品質の初動が可能になる。
また、質問ログが蓄積されることで「そもそもどこが分かりにくいか」が見える。AI検索はサポートを代替するだけでなく、IT運用そのものの改善材料(どの手順が曖昧で、どこが詰まりやすいか)を提供する。
カスタマーサポート(問い合わせ削減と品質の両立)
従来のFAQやシナリオ型チャットボットは、「想定問答の範囲」でしか強くない。一方、顧客の問い合わせは、製品マニュアルの章立てに沿って発生しない。顧客は自分の言葉で状況を説明する。ここに、AI検索の適合性がある。
たとえば顧客は次のように聞く。
- うちの使い方でもこの製品は問題ないか(前提条件が複数ある)
- このエラーはマニュアルのどこを見ればよいか(章名が分からない)
- 返金条件は?例外はある?(規約を読む気がない、ただ結論が欲しい)
AI検索は、マニュアル・FAQ・規約・過去回答テンプレートを横断し、前提条件を確認しながら回答を生成する。ここでの重要点は、回答を“断言”するのではなく、「この条件ならこの対応、例外はこう」という形で判断材料を提示できることだ。RAGは社内の根拠(規約条項など)をコンテキストとして渡すことで、根拠に基づく回答を作りやすくする。【1】
この領域は、自己解決率向上と同時に、オペレーター教育の質を上げる。新人でも過去の回答品質にアクセスできるため、対応の平準化が進む。
提案書・ドキュメント作成支援(知的生産性の底上げ)
AI検索が“効率化”として最も強く見えるのは、提案書・企画書・議事録などのドキュメント生成が絡む領域である。過去の資料が資産化されている企業ほど、AI検索の導入効果が出やすい。
資料側の典型はこうだ。ファイルサーバーに過去の提案書や企画書があるが、探し当てるには「誰がどの案件を担当したか」を知っていないと辿れない。結果として、毎回ゼロから作る。これは企業規模を問わず、非常に多い。
AI検索で成立する問いは次のようになる。
- 「A社向けのDX提案の骨子を作って。過去の同業界提案を踏まえて」
- 「製造業向けの提案で刺さった論点は何だったか。成功パターンを要約して」
- 「同じ課題(属人化、在庫予測など)で提案した過去資料を引いて、構成案を出して」
過去のPowerPointやWordを検索対象にし、類似業種への提案書から構成案や成功事例を抽出してドラフトを作るという使い方が例示されている。【16】
ここでのポイントは、「文章を作る」より前に、社内の過去知見を引き当てて整理するところにAI検索の価値がある点だ。最終成果物の品質は、参照できる社内資産の量と質に強く依存する。つまり、AI検索はドキュメント作成の単なる省力化ではなく、組織の勝ち筋(成功の型)の再利用を促進する。
製造・建設・現場業務(安全、品質、伝承)
現場は、経験の差がそのまま事故率・品質・手戻りに反映される領域である。AI検索の価値は「知っている人が減っても、知っている状態を作る」ことにある。特に、事故・ヒヤリハット・不具合報告・施工記録などは、形式知化されていても活用されにくい典型例だ。
過去の事故事例やヒヤリハット情報を文脈に合わせて提示することで労働災害リスクを低減する、といった方向性が示されている。【16】
ここで重要なのは、「事例がある」だけでは意味がないことだ。現場で必要なのは、いま起きている状況と“似ている部分”を引き当て、何を確認すべきか、どこが危険かを提示すること。AI検索は、報告書の中の類似パターンを拾い、現場の判断速度を上げる。
また、現場報告の効率化として、写真や音声入力を起点に日報の下書きをRAGで生成する活用も進んでいるとされる。【16】 これは検索そのもののユースケースではないが、実務的には重要だ。なぜなら「現場ログが増えるほどAI検索の価値が上がる」ためである。入力負荷を下げてログが増える→検索の価値が上がる→現場がさらに使う、という循環が成立すると、AI検索は単発のツールではなく、業務インフラとして定着する。
経営・意思決定(組織の記憶の再利用)
最後に、AI検索が“最終的に”効いてくる領域が経営・意思決定である。ここでの問いは、データ分析というより、意思決定の背景復元に近い。
- 過去に似た投資判断をしたとき、論点は何だったか
- その施策は、どの理由で却下され、条件は何だったか
- 重要顧客の対応方針は、どの合意で決まったか
議事録、稟議、Slackやメールの意思決定ログを横断して文脈を復元できると、判断の再現性が上がる。再現性が上がると、スピードが上がる。スピードが上がると、機会損失が減る。AI検索は、ここまで到達して初めて「単なる検索機能」を超える。

AI検索がもたらす本質的DX効果 ─ 効率化の先で起きていること
AI検索の導入効果は、初期段階ではどうしても定量指標で語られやすい。
問い合わせ件数が何%減ったか、検索時間が何分短縮されたか、といった数値は、導入判断や投資対効果の説明において分かりやすいからだ。
しかし、それらはAI検索がもたらす変化の「入口」に過ぎない。
より本質的な変化は、組織の中で知識がどのように扱われ、どのように流通するかという構造そのものに現れる。
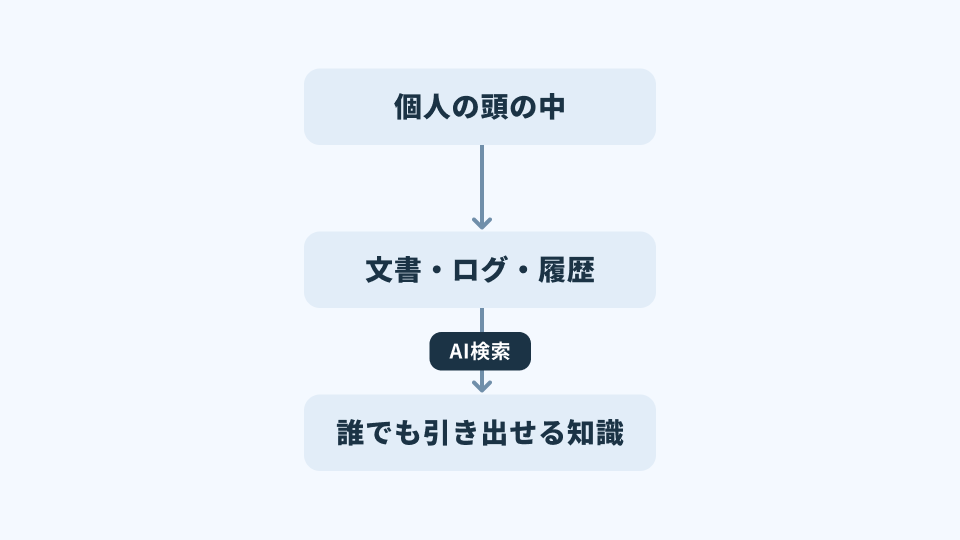
従来、多くの企業では重要な知識が「人」に紐づいていた。
過去の判断理由、例外対応の経緯、失敗から得られた学び。これらは文書化されていたとしても、実際に使えるのは「どこに書いてあるか」「どういう文脈で書かれたか」を知っている人に限られていた。
その結果として起きていたのが、次のような状態である。
- 同じ議論が何度も繰り返される
- 過去の失敗が十分に参照されない
- 担当者が変わると判断の質が揺れる
AI検索は、この構造を根本から変える。
知識を「探せる状態」にするだけでなく、判断に使える状態で引き出すからだ。
ここで起きているのは、単なる業務効率化ではない。
知的資本が、個人の記憶から組織のインフラへと移行するプロセスである。
この変化が進むと、組織は次のような状態に近づく。
- 判断の前提が共有されやすくなる
- 属人性が低下し、引き継ぎコストが下がる
- 意思決定の再現性が高まり、スピードが上がる
DXを「IT導入」と捉えている限り、この変化は見えにくい。
AI検索は、業務フローの一部を自動化するツールではなく、組織の思考プロセスを下支えする基盤として機能し始めている。
中小企業が導入を進める際の現実解
AI検索は強力な技術である一方、導入の仕方を誤ると成果が出にくい。
よくある失敗は、AI検索を「便利な検索ツール」として全社に一気に展開してしまうことだ。
その結果、現場から次のような声が上がる。
- 思ったほど当たらない
- どこまで信用していいか分からない
- 結局、人に聞いた方が早い
これはAI検索の性能が低いからではない。
業務側の準備が整っていないまま導入されていることが原因である。
なぜ最初から全社導入してはいけないのか
AI検索は、業務の曖昧さを増幅させる装置でもある。
業務ルールが整理されていない、文書の粒度がバラバラ、判断基準が暗黙知に依存している――そうした状態でAI検索を全社展開すると、次のことが起きる。
質問は大量に投げられるが、
答えとして返せる情報が整理されていない。
その結果、「答えられない質問」が目立ち、AI検索の評価が下がる。
しかしこれは、AI検索の欠陥ではない。業務の未整理が可視化されただけである。
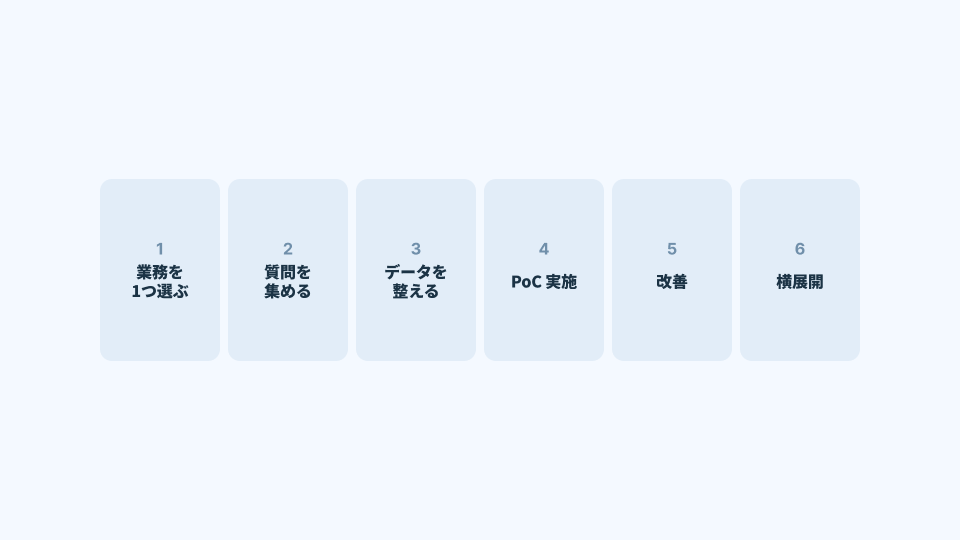
だからこそ、最初に取るべきアプローチは明確だ。
AI検索を「全社の知識を一気に扱う仕組み」としてではなく、特定の業務を深く支える仕組みとして導入する。
業務を1つに絞るという判断の意味
最初の対象業務は、技術的な難易度ではなく、業務特性で選ぶべきである。
問い合わせが多く、
質問のパターンがある程度決まっていて、
成果を測りやすい業務。
たとえば、総務・人事のQ&A、ITヘルプデスク、社内マニュアル検索などは、その典型だ。
ここで重要なのは、「何を答えさせたいか」ではない。
「どんな問いが投げられているか」を正確に把握することである。
AI検索のPoCで蓄積される質問ログは、単なる改善データではない。
それは、業務がどこで詰まり、どこが分かりにくく、どの前提が共有されていないかを示す、極めて価値の高い業務理解データである。
このログを分析することで、
- 文書が足りない箇所
- 表現が曖昧な規程
- 判断が人に依存している領域
が浮かび上がる。
つまりAI検索は、業務を代替する技術ではなく、業務を映し出す鏡でもある。
実装における技術的要件とアーキテクチャ ─ 技術をどう理解すべきか
AI検索の技術構成を理解する目的は、すべてを自社で実装することではない。
重要なのは、どこが精度を左右し、どこが運用上のリスクになるのかを判断できることである。
RAG型AI検索は、一般に次の流れで構成される。
- 業務データ(PDF、Word、ログなど)
- インジェスト・前処理
- 文書分割(チャンキング)
- ベクトル化(Embedding)
- ベクトル検索
- LLMによる生成
この中で誤解されやすいのは、LLMが主役だという認識である。
実際には、精度を左右する最大の要因は前段の設計にある。
- どのデータを対象にするのか。
- 文書をどの単位で分割するのか。
- 文脈をどこまで保持するのか。
これらは技術的な選択であると同時に、業務理解の深さを問う設計判断である。
チャンキングと前処理が重要な理由
業務文書は、AIにとって必ずしも読みやすい形で作られていない。
- 見出し構造が曖昧
- 1文書に複数テーマが混在
- 表記揺れが多い
こうした文書をそのまま投入すると、意味検索の精度は大きく下がる。
そのため、
- 意味単位での分割
- 文脈を壊さないオーバーラップ
- 表記揺れの吸収
といったチャンキングが重要になってくる。分割が粗すぎればノイズが増え、細かすぎれば文脈が失われる。
適切な粒度は、業務文書の性質によって異なる。この作業は、単なる技術作業ではなく、業務の意味構造をどう切り出すかというデータエンジニアリングである。
セキュリティ・ガバナンス・精度評価 ─ 運用で必ず問われる論点
AI検索を業務に組み込むと、「便利さ」と同時に統制が必ず問われる。
最も大きなリスクは、見せてはいけない情報が検索結果に含まれてしまうことである。
そのため実運用では、文書やチャンク単位でのアクセス制御、メタデータによるフィルタリング、高機密データの分離といった設計が不可欠となる。
また、AI検索であっても誤回答がゼロになるわけではない。
重要なのは、誤りを完全に排除することではなく、誤りに気づける設計にすることだ。
- 回答の根拠を明示する
- 参照元を辿れるようにする
- 最終判断は人が行う前提を崩さない
この前提を守ることで、AI検索は「判断を代替する存在」ではなく、判断を支援する存在として機能する。
精度評価も同様だ。
一度作って終わりではなく、どの質問でズレが生じたか、どのデータが不足しているかを継続的に見直すことで、AI検索は初めて業務インフラとして定着する。
まとめ ─ AI検索は「検索機能」ではなく「業務インフラ」である
AI検索は、情報を探すための新しいUIではない。
人が判断するための前提情報を、適切な形で整える業務インフラである。
問うべきは、「AI検索を導入するかどうか」ではない。
「どの業務から、人の思考を拡張するか」である。
この視点を持って導入を進める企業ほど、
AI検索を一過性のトレンドではなく、競争力の源泉として定着させていくだろう。
引用文献
- Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, NeurIPS, 2020
- Pinecone, What is Semantic Search?
- Qdrant, Vector Search and Access Control
- Elastic, Building Semantic Search Applications
- TruLens, Evaluating Retrieval-Augmented Generation
- Ragas, Metrics for RAG Evaluation
- 経済産業省, AI事業者ガイドライン
- 総務省, AI利活用に関するガイドライン
- Kipwise, AI Knowledge Base for SMEs
- Meilisearch, Semantic Search vs Traditional Search







